遗传算法与模型优化
概述
遗传算法(GA,genetic algorithm)是一种基于种群的元启发式算法(metaheuristic algorithms)。(关于元启发式算法参见各种元启发式算法(Metaheuristics)介绍 ),其灵感来自生物进化过程。
遗传算法的基本要素
1.染色体表示(chromosome representation),
2.适应度选择(fitness selection),
3.仿生算子(biological-inspired operators)遗传算法的工作方式
问题参数编码为染色体,再利用迭代的方式进行选择,交叉以及变异等运算来交换种群中的染色体信息,生成符合优化目标的染色体。染色体即对应数据/数组(串式结构)。
遗传算法的基本步骤
1. 编码:GA进行搜索之前对解空间的解数据表示成遗传空间的基因型串结构数据,这些串结构数据的不同组合构成了不同的点。
2. 生成初始群体:随机产生N个初始串结构数据,每个串结构数据生成一个个体,N个个体构成一个群体。GA算法以这个群体为初始点开始进化。
3. 适应度评估:依据实际的问题构造适应性函数。
4. 选择:从当前群体中选出优良个体,使他们有机会作为父代为下一代繁殖子孙。(体现达尔文的适者生存法则)
5. 交叉:(最主要的遗传操作)通过交叉操作得到新一代个体,新个体组合了父辈的个体特性,体现信息交换的思想。
6. 变异:群体中随机选择一个个体,以一定概率随机改变串结构数据中的某个串的值。类比生物界的基因突变,GA算法的变异概率很低,通常取值很小。GA算法的基本结构与遗传算子
此部分将对GA算法的基本结构及其遗传算子进行讨论。
Classical GA Alg
GA算法的伪代码描述如下(Hexo貌似不支持VSCode + Markdown Preview
Enhanced +
pseudocode.js文件魔改之后的伪代码渲染,只好放图了,显得直观些,想了解如何在markdown中写伪代码块参见在 Markdown
中书写伪代码 ) 
简单总结:GA的过程就是生成群体->群体繁衍(交叉互换)->子代基因突变->子代成为新群体->不停迭代,是不是和生物种群的繁衍一模一样。(这就是交叉学科吗)
那么,怎么去确定染色体交叉的概率?论文中给出了公式:
| Variants | Meaning |
|---|---|
| 世代数 | |
| 种群集合的进化世代总数 |
在 GA 的初始阶段,个体之间的相似性很低。R的取值要低,以保证新种群不会破坏个体优良的遗传图式。在进化的末期,个体之间的相似度很高,R 的值也应该很高。
GA 算子
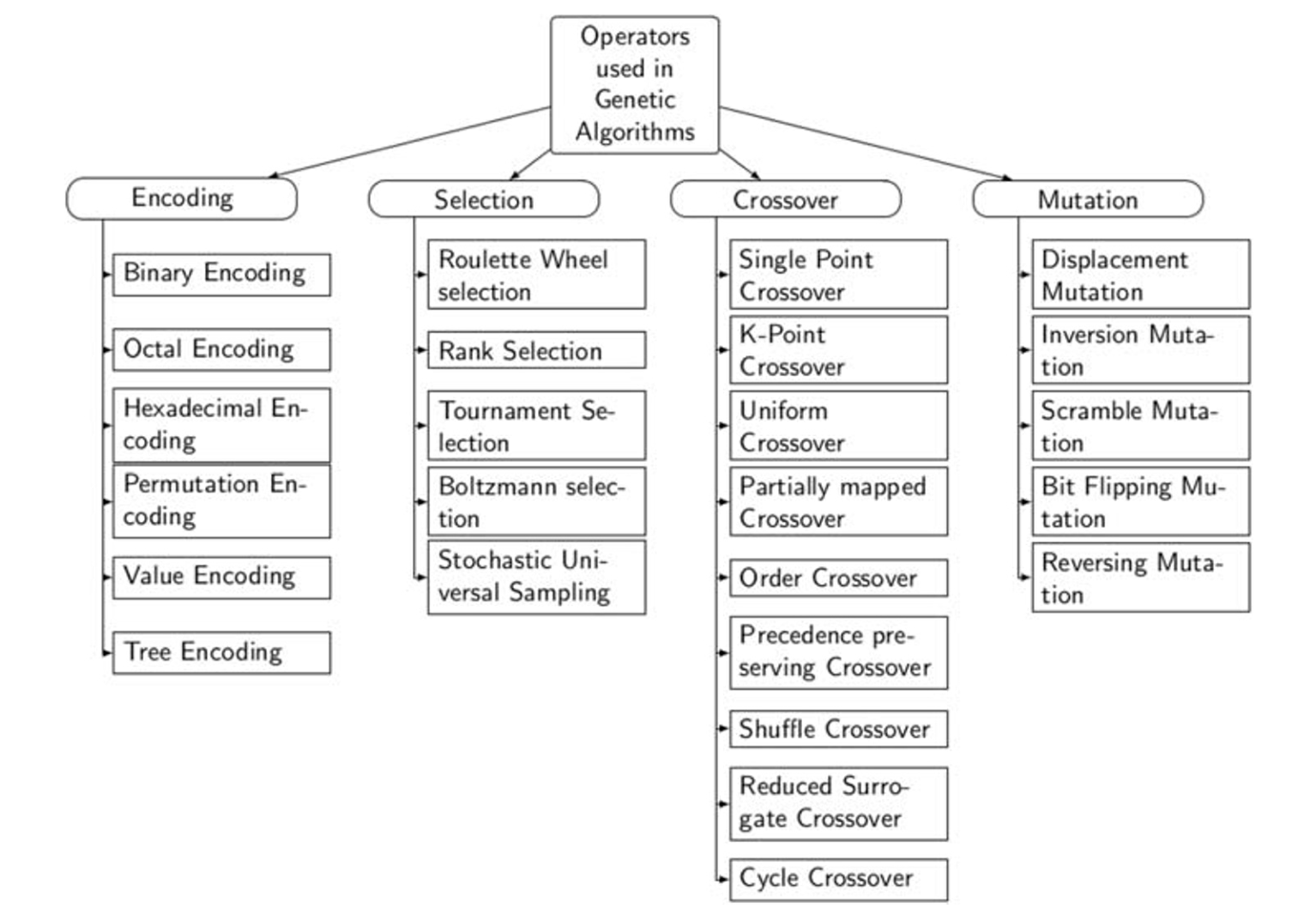
对染色体上的基因(数据串)的编码方案
二进制、八进制、十六进制、排列、基于值和树。(注:原论文中的这一节对基因和染色体这两个概念有混用的现象,不过生物学也存在这种混用,问题不大)。几种编码方式各有优劣,具体对比见如下表格:
| 编码方式 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 二进制 | 易于实施,执行更快 | 不支持反转运算符 | 支持二进制编码的问题 |
| 八进制 | 易于实施 | 不支持反转运算符 | 受限 |
| 十六进制 | 易于实施 | 不支持反转运算符 | 受限 |
| 排列 | 支持反转算子 | 不支持二元运算符 | 任务排序问题 |
| 基于值 | 无需数值换算 | 需要特定的交叉和变异 | 神经网络问题 |
| 基于值 | 无需数值换算 | 需要特定的交叉和变异 | 神经网络找权值问题 |
| 树 | 操作员可以轻松应用 | 一些问题很难设计树 | 不断进化/发展的问题 |
优良个体选择方法
类比进化生物学,进化压力越大,生物受到“物竞天择”的强度越大。GA的收敛速度也取决于选择压力。 常见的选择方法有:轮盘赌、等级排序、锦标赛、玻尔兹曼法、随机通用抽样。具体对比见如下表格:
| 选择方式 | 优点 | 缺点 |
|---|---|---|
| 轮盘赌 | 易于实施,简单,没有偏差 | 有过早收敛的风险,取决于适应度函数中存在的方差 |
| 等级排序 | 保持多样性,没有偏差 | 收敛慢,需要排序,计算量大 |
| 锦标赛 | 保持多样性,并行执行,无需排序 | 锦标赛规模大时多样性的损失 |
| 玻尔兹曼法 | 全局最优 | 计算量大 |
| 随机通用抽样 | 无偏差,快速 | 需要特定的交叉和变异 |
| 精英主义 | 保留种群中最好的个体 | 由于交叉和变异算子,最佳个体可能会丢失 |
交叉运算
通过组合两个或多个父母的遗传信息来生成后代。常见的交叉运算方法有:单点交叉、两点交叉、k点交叉、均匀交叉、部分匹配交叉 (Partially matched crossover (PMX) )、顺序交叉(Order crossover (OX) )、优先保留交叉(Precedence preserving crossover (PPX) )、随机交叉(Shuffle crossover)、减少代理交叉(Reduced surrogate crossover (RCX) )、循环交叉。具体对比见如下表格:
| 交叉运算方式 | 优点 | 缺点 |
|---|---|---|
| 单点交叉 | 易于实施,简单 | 不太多样化 |
| 两点交叉 | 易于实施 | 适用于小子集、不太多样化 |
| 减少代理交叉 | 在小的优化问题上有更好的性能 | 过早收敛 |
| 均匀交叉 | 无偏检索、适用于大型子集、更好的重组潜力 | 不太多样化 |
| 优先保留交叉 | 更好的后代 | 冗余 |
| 顺序交叉 | 更好的探索 | 以前个体的信息丢失 |
| 循环交叉 | 无偏检索 | 过早收敛 |
| 部分匹配交叉 | 更好的收敛率、优于其他交叉 | NA |
变异运算
用于维持从一个种群到下一个种群的遗传多样性的算子。常见的交叉运算方法有:移位突变(Displacement mutation,DM)、单一反转突变(simple inversion mutation,SIM)、乱码突变(Scramble Mutation,SM)。具体对比见如下表格: | 变异运算方式 | 优点 |缺点| | :-------: | :-------: | :-------: | |移位突变|易于实施,适用于小问题实例|有可能过早收敛| |单一反转突变|易于实施|过早收敛| |乱码突变|影响大量的基因、适用于大型问题实例|对种群干扰大、某些问题的解决方案质量下降|
- 标题: 遗传算法与模型优化
- 作者: Eric Zhang
- 创建于 : 2023-03-26 23:38:38
- 更新于 : 2023-12-03 23:43:12
- 链接: https://ericzhang1412.github.io/2023/03/26/02-GA/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。