RNN部分问题的原理解释
1. RNN的前向传播原理
以一个Many-to-Many的简单RNN为例(输入输出维度相等):
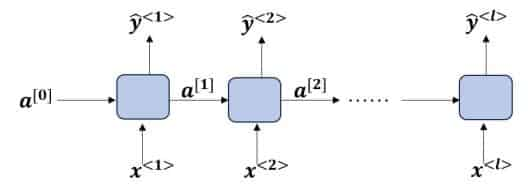
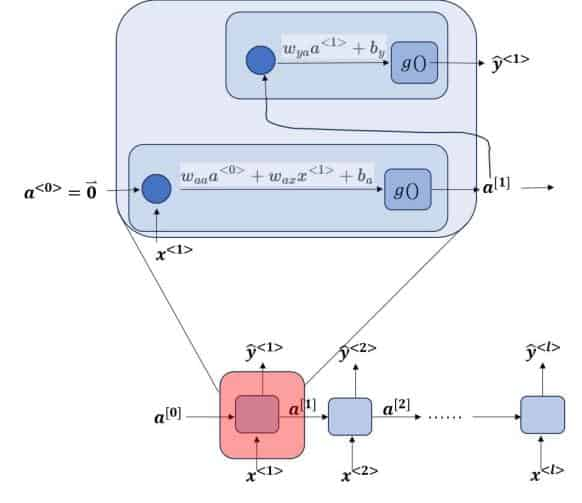
每一时间单位的前向计算过程为:
第一步也可以简写为:
有的RNN论文中还会把第一步的激活函数放到里面,即写作:
这两个公式在宏观意义上被认为是等价的。
2. RNN的损失函数与反向传播(Back Propagation Through Time, BPTT)
现在,通过上一步已经能够找到预测值
模型总的损失函数为:(取时间平均,某些论文也没有做时间平均,个人感觉时间平均没有太大的必要)
优化目标为:
分析可知,优化的目标函数与四个参量有关:
为便于分析,不考虑偏置项对模型收敛的影响,只考虑权重矩阵。首先分析
分两项考虑,第一项:
第二项:
其次分析
在上式中,第一项和第二项不需要循环计算,而第三项是需要不断地计算每一步参数
观察上面的递归式,不难发现有以下的结构规律,对于
下面把
最终算式为
3. RNN的时序记忆能力短的原因?
为便于分析,假设隐藏层的激活函数为线性激活函数(也可以说没有激活),将RNN的前馈输出展开:
不难看出,每一次的前向传播都会对之前的激活值产生影响,一旦序列较长,模型对于附近的值的敏感程度就明显高于之前的输入,RNN表现出了“遗忘”的现象。
4. RNN的梯度爆炸与梯度消失成因?
假定我们使足够简单的线性激活函数作为隐藏层的激活函数
即
假定
且有(待求证?):
如果有
因为
虽然上面的证明(恶补矩阵论去了) )
于是我们能够得出梯度爆炸或梯度消失的充分条件:
梯度爆炸的充分条件:$t
梯度消失的充分条件:$t
以上讨论的都是基于激活函数是线性的(即没有使用任何激活函数)。如果是针对非线性函数,则有非线性函数的输出一定有界这一特性,即:
证明:只要
于是
因为
根据梯度消失的证明思路,我们也很容易得到梯度爆炸的条件:
从微分方程到RNN
令
状态随时间变化可以认为有两部分在作用,其中前者与输入
于是,一个在物理、化学、工程领域非常常见的方程式就出现了:(至少原作者Sherstinsky是这么说的)
除此之外,
加性模型的三个时间向量如下定义:
式中,
该方程是一个具有离散延迟的非线性常延迟微分方程 (DDE)。首项是
5. LSTM的前向传播
在LSTM(以及GRU)中,我们要引入一个新概念:候选记忆元(candidate
memory cell),用

6. LSTM中的BPTT:
基于
单步损失${
优化目标为:
为了便于讨论,依然忽略偏置值对模型的影响,着重考虑权重矩阵。
首先是损失函数关于

公式之所以会分为五项,是因为在反向传播过程中存在两个“分岔路口”。,再往下求解之前一个时刻,则公式内部的
求解
LSTM的时序记忆能力强的原因?
LSTM的核心是前向传播中的记忆单元,通过模型学习,调节三个门函数的权重矩阵的值,有可能会产生
因为有记忆单元的存在,LSTM能实现在较长的时间内“记住”之前的信息。
LSTM对BPTT的梯度爆炸和梯度消失的缓解
LSTM对梯度消失的缓解依然是在更新记忆单元。反向传播的过程中涉及计算
$$
在LSTM迭代过程中,针对
LSTM和ResNet中的残差逼近思想有些相似,通过构建从前一时刻记忆单元到下一时刻记忆单元的“短路连接”,使梯度得已有效地反向传播,以应对梯度消失。
至于梯度爆炸问题,LSTM的提出不能说完全规避,从RNN的单项式连乘到LSTM的多项式连乘,后者还有相加运算,有可能梯度值大于1。毕竟LSTM的提出主要是为了缓解梯度消失的问题。
- 标题: RNN部分问题的原理解释
- 作者: Eric Zhang
- 创建于 : 2023-11-23 11:58:00
- 更新于 : 2023-12-03 23:45:08
- 链接: https://ericzhang1412.github.io/2023/11/23/RNN部分问题的原理解释/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。